Update: this post got featured on Hacker News on 21st November, which is awesome! 😀
My latest spare time project has been writing a general purpose command line heat map tool designed to visualise the distribution of streams of decimal numbers (not necessarily integers) representing something like latency, duration or size. I’ve called it spectro as its output resembles a spectrogram.
It was inspired by this Sysdig tweet for a monitoring tool with built in command line visualisation, and follows on from my distribution Awk script which displays an actual histogram (although it also has some real-time functionality).
You've never seen a command line tool do this. Visualizing real-time latency spectrograms: https://t.co/KiLRNxMnmW pic.twitter.com/TSMrLAGWmM
— Sysdig (@sysdig) July 8, 2015I decided to use this as an excuse to experiment with Go/golang for the following reasons:
- built in simple dependency management (just import and you are good to go)
- easy distribution system (
go get github.com/mrmanc/spectro/spectro) - builds monolithic binaries containing required dependencies
- good set of libraries available
These things combined make it an interesting choice for writing command line tools. You can be sure the tools will work on your system, as they are compiled by go get for your environment. You can be sure that the programs will not be affected by changes in your system packages, as the dependencies are contained in the executable it bakes.
The end result was successful, although I did later find an existing alternative (although this does not do everything I wanted, namely replaying existing log files).
Working with Go
Thankfully there is an Alpha release IntelliJ Idea Go plugin. It provides some assistance with built in types, very basic refactors and syntax checking.
Go has an interesting syntax, and a few quirky features (some good, some hmmm). While I may not agree with all the decisions, it is clear that the language features have been given a lot of thought and display a lot of wisdom. For example, I particularly liked that since map iteration order is not guaranteed, it is actively randomised at runtime to make that clear.
I think the most frustrating part of the language was the constant conversion between various ints, floats etc. The faq elaborates:
“For reasons of portability, we decided to make things clear and straightforward at the cost of some explicit conversions in the code. The definition of constants in Go—arbitrary precision values free of signedness and size annotations—ameliorates matters considerably, though.” — http://golang.org/doc/faq#conversions
So a trade off has been made against clean code to simplify the compiler, ensure portability and mitigate overflows. Okay, overflows are a bad thing, and something that most developers don’t consider so that seems like a good idea. But I would have loved not to have to cast an int returned by an external function to a 64 bit int (where there is no risk of overflow), simply so my code could be less cluttered like the snippet below.
fmt.Fprintf(os.Stderr, "%"+strconv.FormatInt(int64(paddingWidth), 10)+"s %s\r", "", legend)
What does it do?
You can use the provided normal command to generate some test data based on a normal distribution:

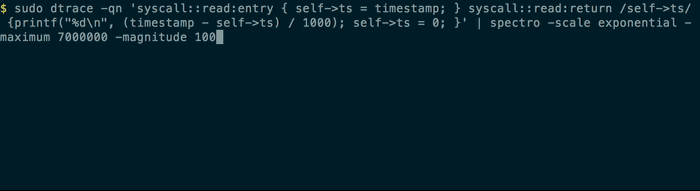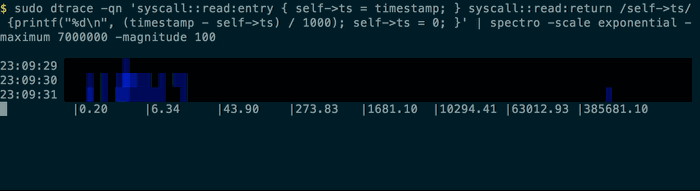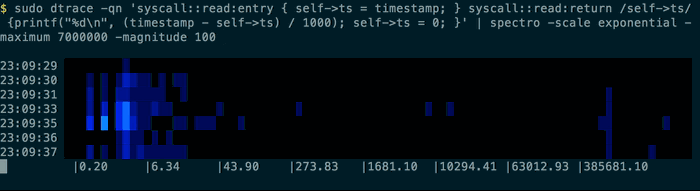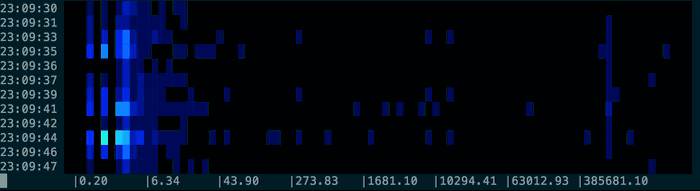
Using dtrace to simulate some real time data for spectro to plot like this: (dtrace example borrowed from this HeatMap tool)
$ sudo dtrace -qn 'syscall::read:entry { self->ts = timestamp; }
syscall::read:return /self->ts/ {
printf("%d\n", (timestamp - self->ts) / 1000); self->ts = 0; }' | spectro -scale exponential
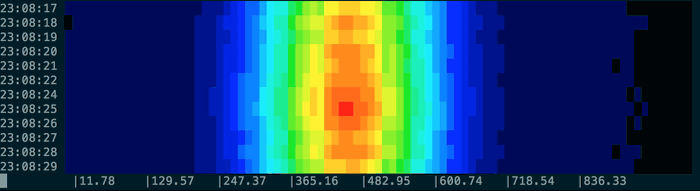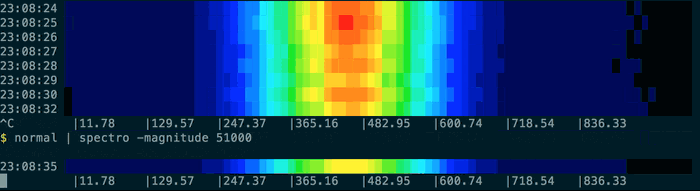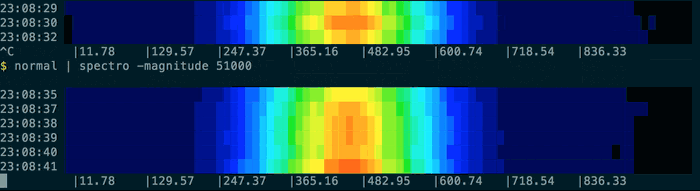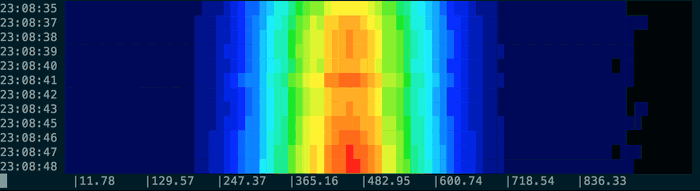
will display something a bit like this in your terminal :
But it really comes into its own if you have historic logs with a formatted time in the line. Here you can use the pacemaker command to indicate to spectro how to sample the data. The pacemaker command will add extra lines to the streamed output as a signal to the spectro command. Pacemaker will look for a time matching something like this: 10:14:52. It’s tolerant of times out of order, but this will result in repeated periods. You can leave the time text in the output, so long as the number you wish to visualise is the last thing in the line.
You can run something like cat sample.log | pacemaker | spectro on the provided sample.log which looks like this:
Tue Nov 11 15:56:20.945 65
Tue Nov 11 15:56:20.989 39
Tue Nov 11 15:56:21.066 41
Tue Nov 11 15:56:21.197 42
Tue Nov 11 15:56:21.245 154
Resulting in output like this:
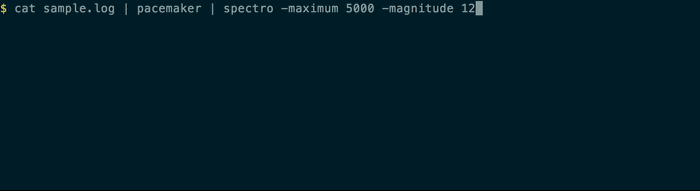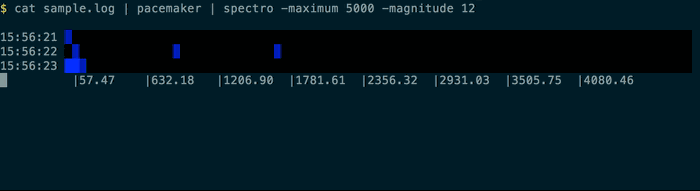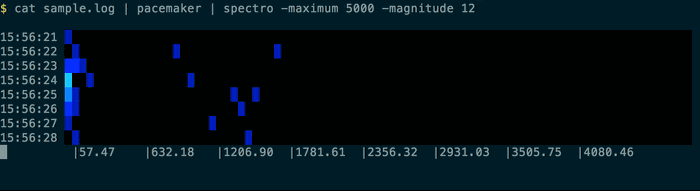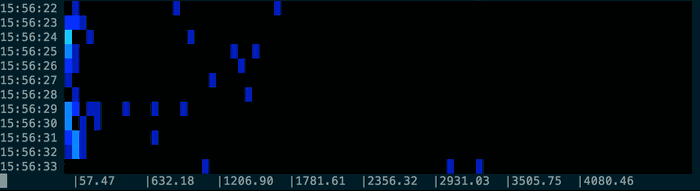
You can use pacemaker -nowait to analyse the file as quickly as possible (otherwise it sleeps between times), and if the log file is still being written to you could just use tail -f sample.log | spectro.
Design
I appreciated the line by line output of sysdig, especially as it allows the user to scroll back as far as their screen history allows. It also means you only have to modify one line of text at once, rather than re-plotting the whole screen.
I decided early on I wanted to find a decent gradient of ANSI colours which covered the visible spectrum. That took a fair time to work out, since there is a lot of bad information out there about ANSI colours, and no list of ‘rainbow’ colours came forward in any search I did. And the rainbow scheme is very attractive when testing with a normal distribution. Frustratingly though, it turned out that lots of colours is actually very difficult to read with a less organised distribution, so I limited it to blue through red.
I was keen to allow data to be streamed in real time, or replayed via an existing log file. While I’m not proud of the hacky time code (which just watches for times like 15:30:05 in the output) it is quite effective at processing an existing log, which can be done ASAP or with simulated pauses.
I was also keen that the charts would adapt to changes in input, so that it is not necessary for the user to provide configuration flags. If the range of inputs changes, the scale will be replotted (an a message printed). Similarly, if the number of points in each bucket changes the magnitude scale will adapt. It is however possible for the user to start these two values at appropriate levels to prevent constant changes.
I pulled the log replay functionality out into a separate command named pacemaker as I can see myself using it again in the future, and also to follow the Single Responsibility Principle and the second of the Tenets of the UNIX Philosophy: ‘Make each program do one thing well’. Communication between pacemaker and spectro is via extra plain text lines to keep things readable, and both are designed to work as filters in a pipeline (tenet nine).
Summary
I think I would recommend using Go for a similar task in the future, simply for the cross platform distribution mechanism, lack of dependency issues and freedom from packaging pain.
I wouldn’t recommend it without further experimenting for large scale projects, or where another language had some distinct advantage in the libraries available.
Go get it
You can find out more, including install instructions at https://github.com/mrmanc/spectro.
Future improvements
- Potentially split the summarisation (histogram) functionality from the rendering, since it is useful on its own and can allow you to use much less space to store a replay of a period in plain text
- Normalise the amplitude using the time since last sample to smooth out results when processing is slow
- Try using a static logarithmic scale for the amplitude scaling to provide consistency and better resolution on small amplitudes
- Allow the user to switch scales dynamically when the command is running
- Use rank based rendering as suggested by this blog post by Dave Pacheco.